
Quote of the Day
If I had to give credit to the instruments and machines that won us the war in the Pacific, I would rate them in this order: submarines first, radar second, planes third, bulldozers fourth.
— Admiral Bull Halsey. I have always found the performance of US submarines during WW2 amazing considering the challenges that they faced with faulty torpedoes.
Introduction

Figure 1: Bathtub Curve Model of System Reliability. (Source)
One of the more distasteful tasks I need to do is make estimates of annual product failure rates using MTBF predictions based on part count methods. I find this task distasteful because I have never seen any indication that MTBF predictions are correlated in any way with field failure rates. This is not solely my observation – the US Army has cancelled its use of part count method MTBF predictions (i.e. based on MIL-HDBK-217). However, the telecommunications industry has continued to use these predictions through their use of Telcordia SR-332, which is similar to MIL-HDBK-217. If you want a simple example of an SR-332-based reliability prediction, see this very clear example from Avago. The parts count method assumes that components fail at a constant rate (green line in Figure 1).
While this calculation is simple, it is useful to discuss why the results generated are so useless – in fact, I would argue that they drive incorrect business decisions for things like required spare parts inventories.
Background
Theory
The basic math here is shown in Equation 1.
| Eq. 1 | 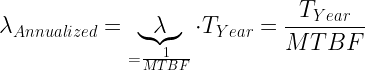 |
where
- λAnnualized is the failure rate per year.
- λ is the failure rate (usually expressed per billion hours).
- TYear is the number of hours in a year (8760)
- MTBF is the Mean Time Between Failures.
Shortcomings
The shortcomings of the part count method are many:
- It assumes a constant failure rate, memory-less failure rate
- A new part fails at the same rate as an old one.
- Total operating hours is all that is important.
- This means 1000 parts operating for one hour fail is the same as one part operating for 1000 hours.
- It assumes that a part's reliability is predictable based on some simple mathematical function.
- I see wide variations in part failure rates that depend on the part's application and how the vendor build it.
- I frequently see lot-dependent component failures.
- Most part failures are not random.
- They are caused by manufacturing issues, misapplication, environmental issues (e.g. lightning), etc.
- In some cases, they are caused by wear-out (e.g. I just dealt with a rash of dried-out, ten-year old electrolytic capacitor failures)
- It assumes that all vendors have the same quality level.
- It assumes that system's failure rate is the sum of all the individual component failure rates.
- Many issues are related to interaction problems.
- Ignores the fact that how you hook up the parts matters.
- Installation issues are a major source of equipment problems.
- I frequently see installations where there is contamination or wind-generated motion that causes device failure.
- I have reported on this blog numerous cases of insect infestation.
- These issues drive field failure rates far more than random part failures.
- The "elephant in the reliability room" is that software failures tend to dominate over hardware failures.
Analysis
Figure 2 shows my calculations for a made-up example.
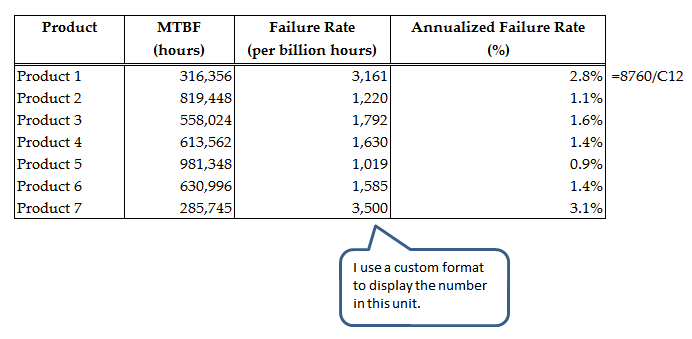
Figure 2: Made-up Example Showing Annualized Failure Rate Calculation.
Conclusion
In general, I find all formal procedures distasteful. In this case, people want a calculation done in a specific manner – and I dutifully comply. However, I know the answer does not reflect reality. In general, these computed annualized failure rates are ~10x what I would consider acceptable annual failure rates for actual products.
I recently had a conversation with an Australian service provider who was having trouble predicting the number of spare parts he needed to have in inventory. The problem he was having traced directly back to this calculation.
Good timing for this article. I just completed a Telcordia SR-332 calculation for one of our products. Of course, I don't believe in the number I calculated. The customer - if he's even remotely aware how these things are calculated - won't believe the number either. For that matter, I've never met anyone that does believe these numbers.
However, the process has been dutifully followed and we've all played our parts correctly. I too wish there was a better way to do this. Right now, we're just all living with (and perpetuating) the same lie.
You would be amazed at the number of folks I talk to who are budgeting people and spares based on these numbers. Not just in the US – all over the world.
Thanks for the note.
mathscinotes
Pingback: MTBF, Failure Rate, and Annualized Failure Rate Again | Math Encounters Blog
Has anyone tried to use demonstrated MTBF numbers for the parts based upon true reliability testing data as opposed to using the estimated numbers from Telcordia data? Curios to know if that is any closer to the AFRs?
People definitely do component accelerated life testing to established measured values. I am designing a laser life test right now! If you want to see an example of the results of this testing, see this post. The testing generally involves running ~150 lasers at high temperature for 2000 hours. In general, the predicted AFRs are less than the actual AFRs. I only use Telcordia predictions for comparisons between assemblies – they do an EXTREMELY poor job of estimating real AFR because AFR in telcom applications is often driven by environmental issues (e.g. lightning, insect damage, etc.) and not random failures or wearout.
mark
What "name" should we assign to software MTBF? How long does it 'seem' to work (as intended) before the inevitable coding 'bug' occurs? (Hint: code size/lines of code, etc.).
Finally - someone lifts the lid on this topic!
I'm debating at the moemment with some collegaues who want to spend another 2 weeks optimising our part-based MTTF numbers .
In my view it doesn't get us any clsoer to the business decision we need to make (what MTBF do we to committ to the customer?)
Can anyone recommend a adjustment factor for the real-world MTBF vs parts-based MTBF for telecoms radio units???
You are participating in one of the great timewasting activities of all time. I cannot count how often I have engaged in this activity at the request of clueless management or customers. I have had this discussion with many quality people over my career and the only value of MTBF calculations (even this value is sketchy) is to provide you with an idea of where your relative failure concerns should be focused. I have spent decades trying to find a correlation of real-world MTBFs to part-count-based calculations. There is none. The real-word failure rate is dominated by factors not related to the parts count method parameters.
If you are making a contractual commitment on failure rate (or its reciprocal MTBF), I would recommend you turn to comparable devices and their historical failure rate. Scale the failure rate appropriately to account for differences in power, application, etc.
I used to give a seminar on MTBF and its early origins. It traces back to the V2 program in WW2.Von Braun hired hired Eric Pieruschka, a German mathematician, to develop a useful approach to modeling system reliability. System failure at that time was dominated by random component failures. That is not true today. Assumptions that were valid in the 1940s and 1950s do not hold with today's component quality levels.